
Обнаружение неисправностей центробежных насосов и электродвигателей с использованием анализа сигнатур тока двигателя и автоматизированного машинного обучения
- 1 — специалист АО «РОТЕК Диджитал Солюшнс» ▪ Orcid
- 2 — канд. техн. наук руководитель департамента АО «РОТЕК Диджитал Солюшнс» ▪ Orcid
- 3 — канд. техн. наук научный сотрудник Университет ИТМО ▪ Orcid
- 4 — канд. техн. наук научный сотрудник Университет ИТМО ▪ Orcid
Аннотация
Центробежные насосы, являясь ключевыми компонентами гидравлических систем, играют фундаментальную роль в обеспечении надежной работы множества промышленных процессов таких отраслей, как энергетика, химическая промышленность и нефтепереработка, где бесперебойная работа оборудования имеет критическое значение. Выход из строя центробежных насосов может привести к значительным финансовым потерям из-за дорогостоящего ремонта и вынужденных простоев производственных линий. В статье представлен инновационный подход к диагностике и выявлению неисправностей центробежных насосов. Этот метод основывается на применении анализа сигнатур тока двигателя (АСТД) в сочетании с технологиями автоматизированного машинного обучения (AutoML). Такой подход позволяет эффективно и с высокой точностью обнаруживать ранние признаки сбоев в работе оборудования. Для проведения экспериментальных исследований использовался открытый набор данных, собранных в условиях, приближенных к реальной эксплуатации. Результатом стала высокая точность выявления неисправностей – 89 %, что значительно превышает показатели традиционного метода на основе градиентного бустинга. Это подтверждает преимущество комплексной модели, сформированной средствами AutoML. Дополнительное повышение точности диагностики стало возможным благодаря использованию усовершенствованного векторного преобразования Парка, примененного к исходным данным о токе и напряжении. При таком подходе выявляются даже малозаметные аномалии в работе насоса, усиливая возможности раннего прогнозирования сбоев. Представленное исследование не только подчеркивает потенциал АСТД как неинвазивного и масштабируемого инструмента для мониторинга состояния оборудования, но и демонстрирует перспективность применения AutoML для задач технической диагностики промышленных насосов.
Отсутствует
Введение
Мировой рынок насосов достиг объема в 59,2 млрд дол. США в 2023 г., причем центробежные насосы составляют его крупнейший сегмент. Эти насосы критически важны для парогазовых электростанций, угольных ТЭС, ядерных реакторов, химических предприятий и других отраслей [1, 2]. Согласно данным Европейской ассоциации производителей насосов, нефтеперерабатывающий завод с производительностью 300000 бар в сутки может эксплуатировать до 650 насосов, каждый из которых требует тщательного мониторинга для предотвращения аварий. Без интеллектуальных систем, способных автоматически анализировать данные с датчиков и выявлять аномалии [3], своевременный контроль такого парка оборудования невозможен.
Одним из перспективных методов мониторинга состояния насосов является анализ сигнатур тока двигателя (АСТД). Этот метод позволяет оценивать техническое состояние оборудования на основе анализа потребляемого тока с использованием недорогих датчиков и проверенных методов обработки сигналов. Особенно эффективен АСТД для центробежных насосов, так как позволяет выявлять проблемы на ранней стадии без прямого доступа к насосу, в отличие от вибрационного, акустического или анализа давления.
Несмотря на потенциал АСТД, его ручное или полуавтоматическое применение требует значительных усилий экспертов и разработчиков, что затрудняет масштабирование на большое количество оборудования. Решением могут стать системы диагностики на основе машинного обучения (МО), исследуемые более 15 лет. Большинство работ по АСТД сосредоточено на диагностике электродвигателей – обрыва стержней ротора [4, 5], неисправностей обмотки статора [6] и дефектов подшипников [7-9]. Типичные подходы включают расчет признаков во временной, частотной и время-частотной областях [10-12], демодуляционные преобразования [13, 14] и их комбинации с различными моделями МО. Однако исследований, посвященных насосам, крайне мало из-за недостатка качественных данных. Большинство работ основано на синтетических данных [8] или лабораторных установках [15, 16], что ограничивает применимость результатов в реальных условиях. Исключением является исследование C.E.Sunal и др. [9], использовавших промышленные данные центробежных насосов. Однако технические детали реализации в нем недостаточно раскрыты.
Классические методы МО и глубокое обучение (ГО) перспективны [17], но ограничены малым объемом размеченных данных. На практике классическое МО способно решать задачи при ограниченном количестве данных. Однако при таком подходе крайне важно создание информативного признакового пространства. Эффективным подходом подготовки дополнительного информационного сигнала для анализа оборудования и создания признаков остается использование метода расширенного векторного преобразования Парка, которое нивелирует влияние частоты питания и выделяет признаки неисправностей [18]. Развитие автоматизированного машинного обучения (AutoML) также открывает новые возможности. AutoML упрощает предобработку данных, построение моделей и настройку гиперпараметров, обеспечивая эффективное использование данных даже при их дисбалансе [19-21].
Цель настоящего исследования – разработка методики выявления неисправностей насосной установки с электродвигателем на основе сигнатур тока с учетом ограниченного количества данных. Для этого решались задачи по поиску оптимального комбинированного подхода, включающего приемы АСТД, генерацию характерного признакового пространства и AutoML при классификации неисправностей центробежных насосов и электродвигателей на ранней стадии с использованием открытого набора данных, имитирующего реальные условия. Рассматривается сценарий, когда схожая по своим проявлениям в сигнале неисправность может присутствовать как в электродвигателе, так и в насосе. В серии экспериментов оценивалось влияние расширенного векторного преобразования Парка на точность диагностики. Результаты показали, что AutoML позволяет автоматически создавать модели с точностью свыше 89 %, превосходящей оптимизированный градиентный бустинг. Это подтверждает потенциал AutoML для задач промышленной диагностики.
Литературный обзор
Анализ сигнатур тока двигателя насосов и электродвигателей
Для обнаружения аномалий и классификации неисправностей насосов и двигателей с использованием АСТД предложено несколько подходов [22]. Один из последних методов, представленных Y.Han и др. [15], фокусируется на неконтролируемом обнаружении аномалий с использованием комплексной системы на основе АСТД, расширенного векторного преобразования Парка, CNN-LSTM attention-модели и спектрального анализа. Модель пытается восстановить мгновенную амплитуду тока, используя исходные фазы и дополнительные признаки напряжения. Авторы провели глубокий анализ и вручную выделили три уровня кавитации и количество поврежденных лопастей рабочего колеса. Решение принималось на основе статистически рассчитанного порога в частотной области и остаточной разницы между измеренными и прогнозируемыми значениями. Все задачи решались в условиях переменного расхода.
C.E.Sunal и др. в статье [9] применили классический подход, визуализируя компоненты вектора Парка. Они достигли точности от 85,5 до 100 % (в зависимости от частоты дискретизации сигнала) в задаче классификации изображений с использованием дообученной модели ResNet-34. Визуальное представление решило проблему дисбаланса данных за счет эффективного аугментирования уже существующих. Модель обучалась и валидировалась на частотах 1500 и 3000 Гц, а тестовые данные включали 1500, 3000 и 4500 Гц. Данные были собраны с насосов в различных рабочих режимах. Этот подход позволил решить задачу контролируемого обнаружения аномалий, идентифицируя поврежденные насосы. Детальный обзор работ тех же авторов [8] показывает, что модели глубокого обучения способны решать задачи обнаружения неисправностей двигателей и насосов с высокой точностью. Лишь небольшая часть классических моделей машинного обучения достигает точности выше 90 %.
Однако в этих исследованиях отсутствует информация о степени тяжести неисправностей. Сигналы развитых дефектов можно выявить визуально с помощью частотного анализа, но эксперты могут столкнуться с трудностями при обнаружении слабовыраженных аномалий. Неисправности могут маскироваться в боковых полосах несущей частоты или частоты подшипников, оставаясь незаметными после демодуляции из-за низкой спектральной мощности гармоник дефекта и высокого уровня шума. Методы машинного обучения позволяют прогнозировать возникающие неисправности, но ограниченный объем данных может критически влиять на модели глубокого обучения, приводя к их переобучению. Дополнительная сложность возникает при изменении режима работы насоса или двигателя, что требует сбора новых данных.
Применение AutoML в обнаружении неисправностей
Изначально AutoML фокусировалось на автоматизации типичных задач инженеров МО, делая машинное обучение доступным для экспертов предметной сферы. Однако развитие области показало, что AutoML способно превзойти человека в проектировании архитектур моделей как для классического МО [23, 24], так и глубокого обучения [25]. Существует множество AutoML-фреймворков, но, насколько известно авторам, лишь два из них (FEDOT и TPOT [26]) могут не только автоматизировать поиск моделей и оптимизацию гиперпараметров, но и генерировать композитные модели с использованием генетических алгоритмов для улучшения результатов. Композитная модель – особый тип ансамблей, напоминающий стекинг. Она может быть представлена в виде графа, где каждый узел соответствует модели или методу обработки данных. Комбинируя узлы и связи, можно получить оптимальную структуру для конкретных данных.
Предыдущие исследования в области диагностики неисправностей с использованием AutoML демонстрируют, что такие подходы позволяют создавать сложные модели с более высокой точностью, чем одиночные алгоритмы. J.Zhang и др. [12] показали, что TPOT превзошел SVM и XGBoost, достигнув точности от 95,8 до 99,3 % при различном соотношении сигнал/шум в вибрационных сигналах. Используя вейвлет-разложение, A.S.Maliuk и др. в статье [27] успешно классифицировали три типа повреждений подшипников (внутреннее кольцо, внешнее кольцо, шарик) и нормальное состояние. Аналогично, R.H.Hadi и др. в работе [28] отмечали, что AutoML-фреймворк PyCaret достиг точности 95,6 % на новых данных без использования композитных моделей. M.Cerrada и др. в статье [29] сравнили результаты TPOT и H2O [30] в задаче классификации степени тяжести трех типов неисправностей зубчатых передач. Оба фреймворка показали схожую точность (более 96 %) во всех сценариях, сопоставимую с другими методами МО и ГО. Авторы отметили, что важные признаки, используемые моделями, совпадали, несмотря на различия в архитектурах.
Главное преимущество FEDOT перед TPOT и другими фреймворками – возможность создания моделей с высокой вариативностью. Под высокой вариативностью композитных моделей понимается возможность создания ацикличного направленного графа, где вершинами являются операции предобработки данных или обученные модели, а ребра задают направление передачи результата между вершинами. FEDOT позволяет соединить предшествующие вершины с вершинами любых последующих. Таким образом FEDOT реализует метод, обобщающий подход создания композитных моделей в TPOT. Кроме того, FEDOT поддерживает разнообразные типы данных и задач, предлагая гибкий интерфейс взаимодействия. Исследований с применением FEDOT для диагностики двигателей крайне мало. В работе I.Revin и др. [31] протестировали FEDOT на задачах классификации временных рядов, используя публичные наборы данных. В 90 % случаев эффективность композитных моделей FEDOT превзошла или приблизилась к современным алгоритмам, что подтверждает их применимость для задач, аналогичных обнаружению неисправностей.
Методы
Экспериментальные данные
Публично доступные наборы данных для анализа тока и напряжения электродвигателей, особенно с подключенными насосами, ограничены. Большинство существующих наборов охватывают узкий спектр типов неисправностей, мощности двигателей и режимов работы. Однако S.Bruinsma и др. в работе [7] предложили набор данных, частично решающих эти проблемы. Набор включает трехфазные токи и напряжения, зарегистрированные после частотного преобразователя асинхронных двигателей мощностью 11 и 22 кВт, а также вибрационные сигналы с пяти точек двигателя и насоса. Данные записывались с частотой дискретизации 20 кГц. Электрические сигналы фиксировались в течение 15 с паузой 2 мин между измерениями. Сигналы никак не обрабатывались, сырой 24-битный сигнал был записан в чистом виде в CSV-файл. Всего зарегистрировано 20 типов неисправностей с тремя уровнями тяжести для каждого. Данные для исправного состояния были замерены 94 раза, для остальных дефектов количество фиксаций варьируется от 3 до 10. Исходя из этого можно сделать вывод, что набор не сбалансирован – доля исправных состояний превышает неисправные в соотношении примерно 5:1. Разметка данных проведена автоматически в момент их записи, каждая неисправность записывалась отдельно. Данные не были валидированы независимыми экспертами, собирались при различных скоростях двигателя, что повышает их применимость в реальных промышленных условиях. Несмотря на усилия авторов, этот набор в исследованиях о токовой диагностике насосов почти не использовался.
Для экспериментов выбран минимальный уровень тяжести неисправностей, так как основная цель – раннее обнаружение. Использованы измерения при 100 %-ной скорости двигателя. Решалась задача многоклассовой классификации с семью классами: исправное состояние, повреждения подшипников двигателя (внутреннее и внешнее кольца, шарик), повреждение подшипника насоса (одновременно внутреннее и внешнее кольца), ослабление крепления двигателя и насоса. Данные были предварительно проанализированы для изучения свойств сигналов до и после предобработки, а также нахождения выбросов. Выбранные семь классов являются наиболее трудными для анализа на наличие дефекта. Повреждения в наборе данных создавались искусственно. Повреждения колец подшипников были нанесены со стороны элементов качения с помощью фрезы и представляют борозды по ширине всего кольца длиной 1 мм и глубиной 350 мкм. Степень повреждения различалась количеством этих царапин. Сами же тела качения были повреждены гравером по всей поверхности шара, повреждения имеют вид царапин по всей поверхности шаров [7]. Крепления болтов уменьшили, ослабив уже закрученные болты.
Предобработка данных и извлечение признаков
Исходный набор содержит файлы для каждой фазы и типа сигнала, где столбцы соответствуют 15-секундным измерениям. Файлы преобразованы в массив размером Nsamp×Nchan, где Nchan= 6 (три фазы тока и напряжения). Массив включает все доступные данные для исправных и неисправных состояний с соответствующими метками классов. В тестовый набор выделены 30 % измерений каждого состояния.
В части экспериментов добавлены дополнительные каналы данных с использованием расширенного векторного преобразования Парка (до шести каналов). Это преобразование улучшает диагностику трехфазных электромашин, минимизируя влияние несущей частоты (50 Гц) и выделяя признаки неисправностей. Например, расширенное преобразование Парка для тока описывается линейной комбинацией трех фаз, что упрощает анализ асимметрии и гармоник:
где iu, iv, iw соответствуют трем фазам тока, а ia, ib – действительной и мнимой компонентам вектора Парка.
Линейное преобразование позволяет получить до четырех каналов данных (два для тока и два для напряжения). Эти векторы также могут быть использованы для формирования до четырех дополнительных каналов путем вычисления квадрата модуля вектора Парка:
где iinst – мгновенная амплитуда.
Это преобразование удаляет основную частоту 50 Гц из сигнала. После формирования дополнительных каналов массив выборок делился на временные окна длительностью 1 с (20000 отсчетов на окно) и преобразовывался в трехмерный тензор. Размерности тензора соответствовали количеству окон, размеру окна, числу каналов данных. Для каждого окна выполнялось извлечение признаков согласно стандартной практике АСТД [32]. Рассчитывались признаки временной и частотной областей, включая среднее значение, дисперсию, среднеквадратичное значение (RMS), коэффициент амплитуды (crest factor), эксцесс, асимметрию.
Энергия приближенных коэффициентов первого, второго и третьего разложений вейвлет-пакета была добавлена во временно-частотной области. В общей сложности для каждого канала данных рассчитано 28 признаков, что привело к формированию до 224 признаков. Полный список признаков приведен в табл.1. На завершающем этапе к обучающему и тестовому наборам данных применялось масштабирование min-max.
Таблица 1
Сгенерированные функции
|
Домен времени |
Частотный домен |
||
|
Среднее значение |
|
Среднее значение |
|
|
Дисперсия |
|
Дисперсия |
|
|
Среднеквадратичное значение |
|
Среднеквадратичное значение |
|
|
Пиковое значение |
PVtime = max (|x|) |
Пиковое значение |
формула
|
|
Крест-фактор |
|
Крест-фактор |
|
|
Куртозис |
|
Куртозис |
|
|
Скошенность |
|
Скошенность |
|
|
Коэффициент зазора |
|
Частота пикового значения |
|
|
Линейный интеграл |
|
Энергия спектра |
|
|
Импульсный фактор |
|
Домен времени и частоты |
|
|
Фактор формы |
|
Энергия детальных коэффициентов вейвлет-пакетного разложения |
|
|
Размах |
|
Энергия аппроксимирующих коэффициентов вейвлет-пакетного разложения |
|
|
Энтропия Шеннона |
|
|
|
В рамках исследований сформировано четыре набора данных для изучения влияния дополнительных каналов на эффективность диагностики неисправностей с помощью АСТД. Первый набор данных (NoPark) содержал только предварительно обработанные исходные данные о токе и напряжении в качестве базового уровня для оценки улучшения точности классификации за счет добавления компонентов вектора Парка. Второй набор данных – только векторы мгновенного тока и напряжения. Данный набор использовался для оценки эффекта демодуляции метода расширенного вектора Парка и сравнения выразительности данных с необработанным током и напряжением. Третий набор – комбинация двух предыдущих. Это основной набор для исследования эффективности предложенных алгоритмов, так как содержит наибольшее количество информации о сигнале. Четвертый набор включал компоненты вектора Парка, а также мгновенную амплитуду. Четвертый набор данных применялся для оценки количества информации о неисправностях в компонентах вектора Парка (каждая компонента представляет линейную комбинацию трех фаз) и уменьшения размерности пространства признаков. Табл.2 содержит информацию о каждом наборе данных, использованном в экспериментах.
Таблица 2
Наборы данных
|
Эксперимент |
Используемые данные |
Размер обучающего набора данных (количество семплов ´ количество признаков) |
|
NoPark |
Три фазы тока и напряжения |
1680 × 168 |
|
OnlyInstAmp |
Мгновенная амплитуда тока и напряжения |
1680 × 56 |
|
WithInstAmp |
Три фазы и мгновенная амплитуда тока и напряжения |
1680 × 224 |
|
FullPark |
Векторы Парка и мгновенная амплитуда |
1680 × 168 |
Алгоритмы классификации
Для классификации неисправностей использовалось два подхода. Во время предварительного обучения алгоритм градиентного бустинга показал лучшие результаты по сравнению с другими классическими методами машинного обучения. Такой результат соотносится с общим мнением о том, что градиентные бустинги наилучшим способом справляются с задачами. Таким образом, первый подход включал использование градиентного бустинга на деревьях решений с реализацией библиотеки CatBoost [33]. Классификатор CatBoost был обучен с использованием гиперпараметров, оптимизированных с помощью фреймворка настройки Optuna [23].
Для выборки гиперпараметров в Optuna применялся алгоритм Tree-structured Parzen Estimator [24, 34] с 10 начальными запусками. В роли адаптивного алгоритма обрезки (pruner) использовался алгоритм Hyperband [34] с минимальным числом ресурсов – 50, максимальным – 400, коэффициентом уменьшения – 2 и количеством бутстрэпных выборок – 10. Благодаря многопоточности Optuna удалось значительно ускорить оптимизацию гиперпараметров, протестировав около 3000 вариантов в каждом экспериментальном сценарии. Максимальное количество итераций обучения для CatBoost – 400.
В процессе оптимизации Optuna настраивались следующие гиперпараметры: целевая функция потерь – MultiClass (многоклассовая) или MultiClassOneVsAll (многоклассовая OneVsAll); скорость обучения – от 0,01 до 1 с шагом 0,001; регуляризация на листьях L2 – от 1 до 200 с шагом 1; тип бустинга – Ordered (упорядоченный) или Plain (стандартный); формула расчета весов классов – Balanced (сбалансированные) или SqrtBalanced (сбалансированные через квадратный корень); глубина деревьев – от 1 до 10 с шагом 1; доля признаков (процент случайного подпространства) – от 0,01 до 1 с шагом 0,01.
Во втором подходе применялась открытая платформа AutoML под названием FEDOT [20] для решения той же задачи классификации. Платформа FEDOT способна автоматически формировать, оптимизировать и настраивать композитные модели, используя представление в виде направленного ациклического графа и генетические алгоритмы. В рамках исследования использована предварительная установка «наилучшее качество». Она позволяет использовать любые доступные модели машинного обучения при создании композитной модели.
Критерий ранней остановки был установлен на 10 поколений без улучшений, а максимальное количество поколений – на 100. Во время настройки гиперпараметров с помощью Optuna максимизировалась макросредняя F1-мера на тестовом наборе данных. В случае создания композитной модели фреймворк FEDOT самостоятельно пытался максимизировать макросреднюю F1-меру с использованием пятикратной перекрестной проверки. Для минимизации влияния дисбаланса классов использовалось усреднение по макроклассам. Поскольку фреймворк FEDOT не поддерживает усреднение по макроклассам, была реализована собственная метрика.
Результаты
Разведочный анализ данных
Исходный зарегистрированный сигнал представлен на рис.1. Форма сигнала значительно отличается от идеальной синусоиды из-за использования частотного преобразователя, причем наибольшие искажения наблюдаются в напряжении. Анализ распределения сигналов показал, что между исходными данными исправных и неисправных состояний нет значимых различий. Однако в данных исправного состояния (healthy 1 при скорости 100 %, 15-е измерение) обнаружен процесс остановки двигателя, который был исключен как выброс.
Расширенное преобразование Парка позволило перейти к альтернативному представлению данных. Влияние преобразования на спектр сигнала показано на рис.2. В качестве уровня серьезности 3 был взят сигнал двигателя с поврежденным наружным кольцом подшипника. Демодуляция позволяет перераспределить амплитуду спектра на другие частоты, что облегчает выявление неисправностей. Преобразование Парка подавляет несущую частоту питания, увеличивая амплитуды других значимых гармоник. Это изменяет распределение сигнала при сравнении исправных и неисправных состояний, что впоследствии влияет на распределение генерируемых признаков.
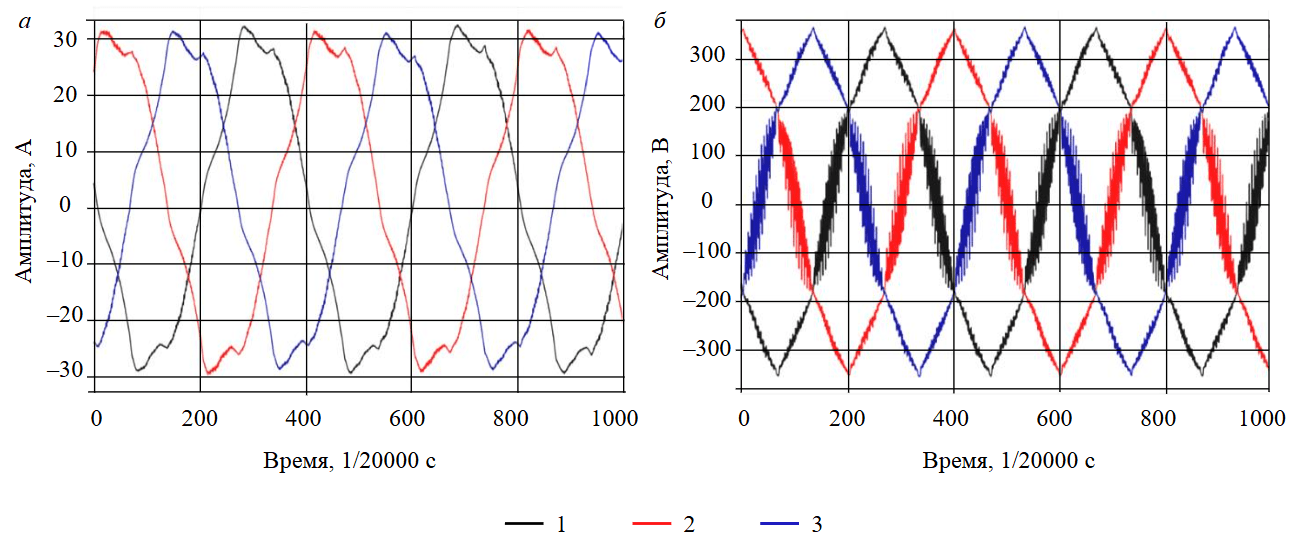
Рис.1. Исходный сигнал тока (а) и напряжения (б)
1, 2, 3 – фазы
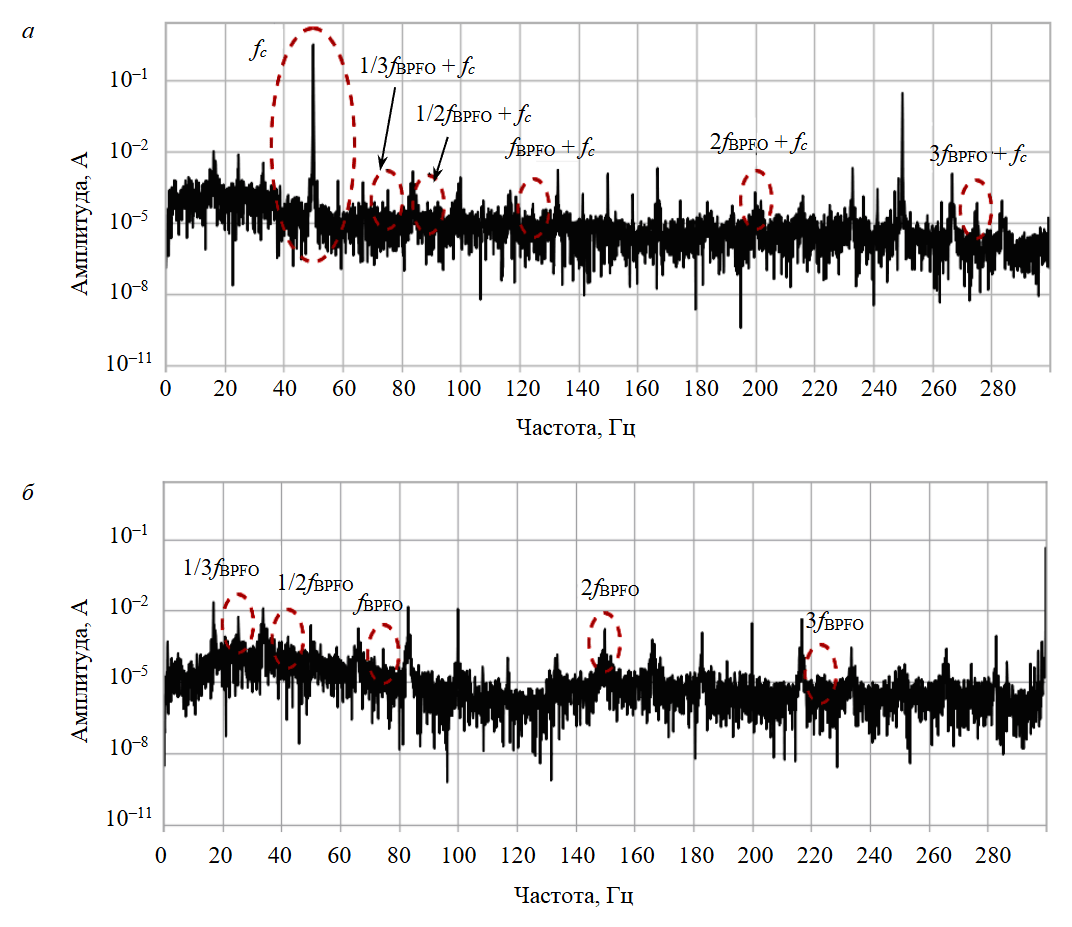
Рис.2. Сравнение спектра исходного сигнала тока и мгновенной амплитуды: а – спектр мгновенного тока фазы; б – спектр обобщенного тока после преобразования Парка
fc – несущая частота 50 Гц; fBPFO ≈ 74,7 Гц в зависимости от используемой частоты вращения подшипника и электродвигателя
Проведен визуальный анализ компонент вектора Парка. На рис.3 показано различие между повреждением внешнего кольца подшипника (BPFO) с уровнями тяжести 1 и 3 при 100 %-ной скорости двигателя. Основное отличие между исправным состоянием и обоими неисправными обусловлено большим объемом данных исправного состояния. Однако видно, что паттерн уровня 3 более искажен и асимметричен по сравнению с уровнем 1, который близок к исправному состоянию. Это косвенно указывает на сложность обнаружения неисправностей на ранних стадиях даже методами машинного обучения.
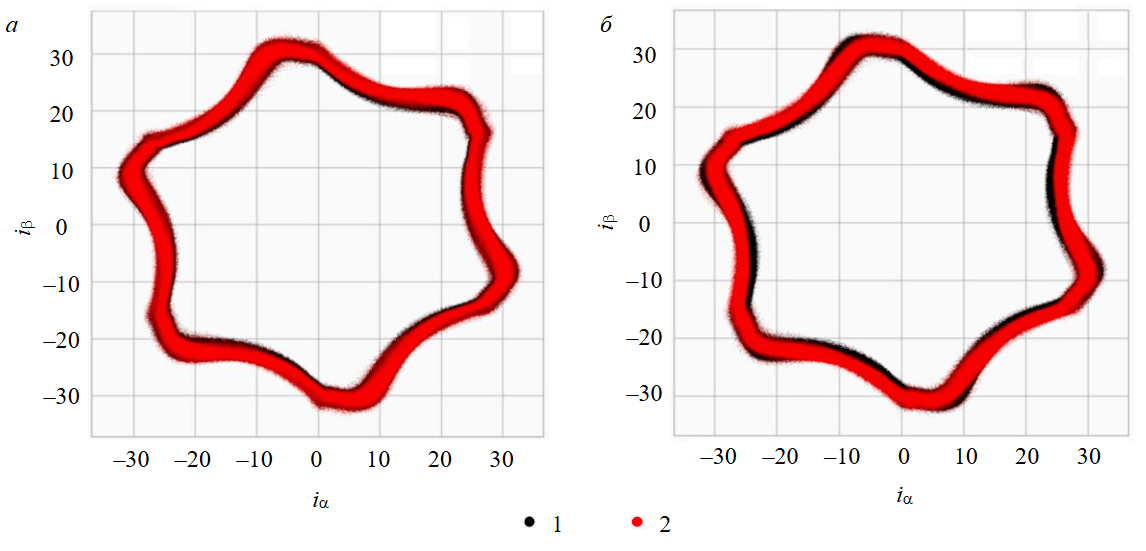
Рис.3. Сравнение структуры векторных компонентов Парка для уровня серьезности 1(а) и уровня серьезности 3(б) неисправностей и состояния без сбоев
1 – компоненты преобразования парка, не связанные с неисправностями, одинаковые для обоих графиков; 2 – компоненты неисправностей, которые зависят от уровня серьезности для каждого участка; ia и ib – действительная и мнимая компоненты вектора Парка
Анализ распределения признаков с использованием диаграмм размаха подтвердил, что предложенные признаки объясняют различия между классами и могут улучшить качество классификации. На рис.4 представлены три информативных признака: сгенерированный на основе исходных данных напряжения; полученный из спектра a-компоненты преобразования Парка; рассчитанный через вейвлет-пакетное разложение мгновенного тока. Каждый из них может эффективно использоваться для обучения моделей МО.
Анализ результатов AutoML
На генерацию композитных моделей машинного обучения выделялось 30 мин, а настройку гиперпараметров – 5 мин. Эксперименты проводились в три этапа:
- Базовый уровень: комбинация генератора квантильных признаков и модели случайного леса.
- Сравнение с SOTA: лучший результат предложенного подхода сопоставлялся с результатами других моделей классификации временных рядов по метрике F1.
- Ансамблирование: признаки моделей с наивысшими метриками объединялись в единую матрицу, после чего повторялся процесс выбора модели.
На рис.5 визуализирован процесс композиции моделей. Наблюдается рост качества моделей с каждым поколением и стабилизация метрик, что подтверждает способность FEDOT сходиться к оптимальному решению за разумное время. Анализ разнообразия популяции моделей показал, что вначале распределение метрик широкое, что отражает вариативность производительности. На поздних этапах распределение сужается с ростом целевой метрики и снижением стандартного отклонения. Эволюционная оптимизация обеспечивает как высокое качество, так и сохранение разнообразия моделей даже на финальных поколениях.
Преимущества подхода перед традиционным градиентным бустингом:
- Гибкая композиция моделей – примеры созданных пайплайнов (рис.6) демонстрируют способность фреймворка комбинировать разнородные методы предобработки и алгоритмы.
- Автоматизация трудоемких этапов – автоматический подбор признаков, моделей и гиперпараметров сокращает время разработки.
- Результаты подтверждают, что интеграция AutoML и АСТД позволяет создавать эффективные системы диагностики для промышленного оборудования.
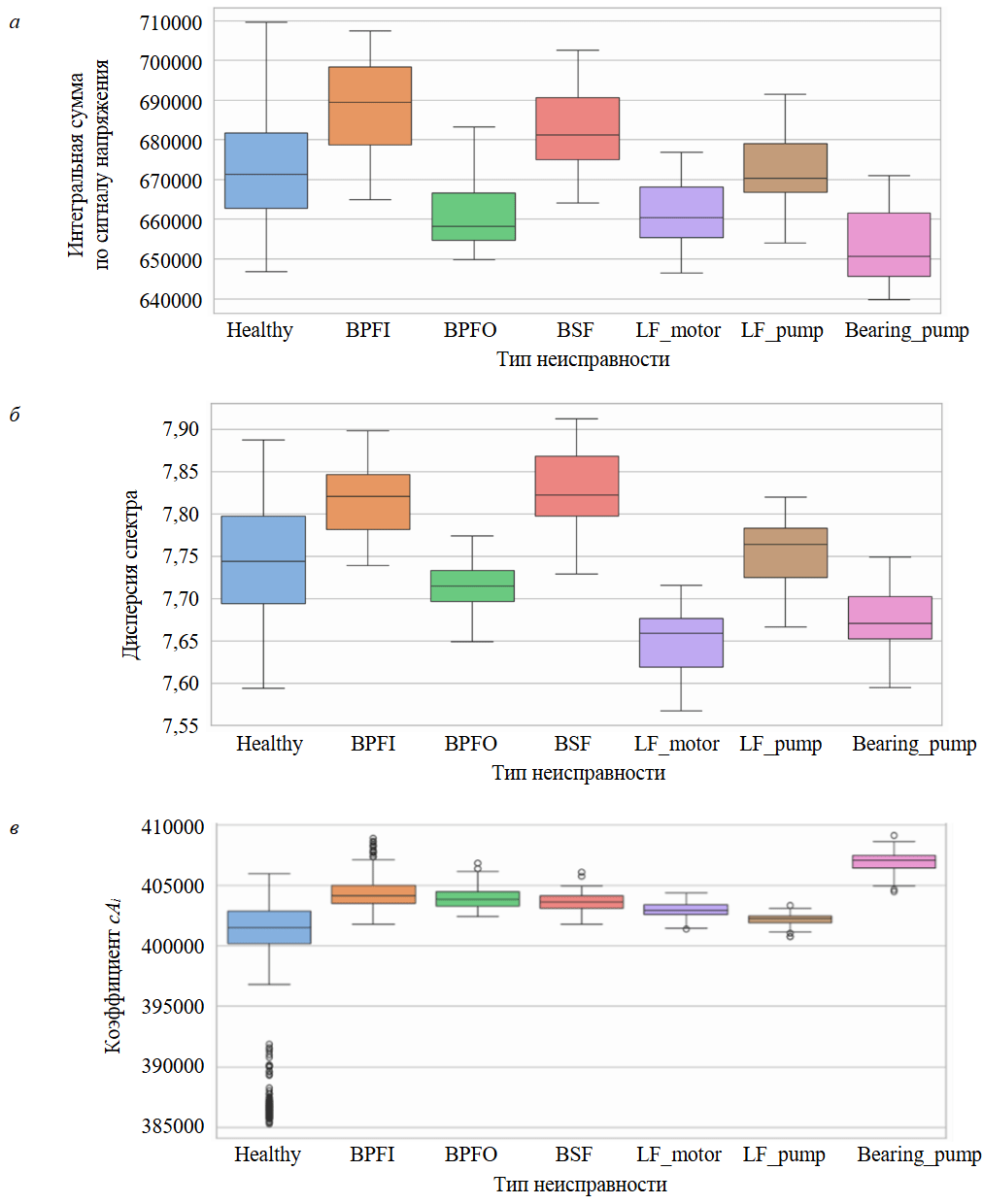
Рис.4. Пример распределения извлеченных объектов: а – первая фаза напряжения, линейный интеграл; б – рассчитанная дисперсия спектра; в – моментальная амплитуда тока, коэффициент сАi (энергия аппроксимирующих коэффициентов вейвлет-пакетного разложения)
Healthy – отсутствие каких-либо повреждений; BPFI, BPFO и BSF – неисправности, связанные с повреждениями внутренних, наружных колец и шариков подшипника двигателя; LF_motor и LF_pump – проблема опоры двигателя и насоса; Bearing_pump – неисправность подшипников насоса, у которого повреждены оба колеса
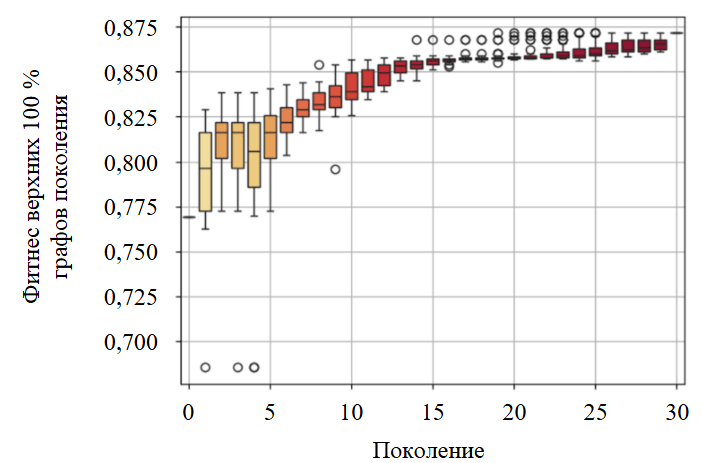
Рис.5. Эволюция производительности композиции моделей

Рис.6. Примеры композитных пайплайнов, созданных AutoML: a – линейный пайплайн с бустингом; б – линейный пайплайн с перцептроном
Вычислительные узлы: normalization – нормализация; scaling – масштабирование; lgbm – облегченная модель градиентного бустинга; logit – логистическая регрессия; rf – алгоритм случайного леса; mlp – многослойный перцептрон
Оценки обученной модели
Макро F1-оценки для обоих алгоритмов, измеренные на тестовом наборе данных, представлены в табл.3. Алгоритм CatBoost смог достичь максимальной макро F1-оценки 0,68, проведя обучение на данных без преобразования Парка. Модель, обученная на других наборах данных, показала немного худший результат с почти аналогичной оценкой. Фреймворк FEDOT продемонстрировал лучший результат, достигнув более 0,89 макро F1-оценки. Лучшая модель обучена на данных с комбинированными необработанными и мгновенными амплитудными сигналами. Композитная модель начинается с узла ресемплинга, который не применяет никаких преобразований в случае многоклассовой задачи. Второй узел применяет алгоритм FastICA с унитарным приведением к единичной дисперсии (whitening) без уменьшения размерности и передает результат следующему узлу. Третий узел – это модель логистической регрессии с обратной силой регуляризации C = 5,88. Узел нормализации представляет операцию масштабирования по методу min-max, применяемую к вероятностям из логистической регрессии. Последний узел представляет квадратичный дискриминантный анализ (QDA), примененный к нормализованным вероятностям. Полученный пайплайн прост в понимании и интерпретации, он может показать, что данные подготовлены, и предоставляет всю необходимую информацию о неисправностях. Даже в случае, когда неисправности электрического мотора и насоса могут давать схожие спектральные характеристики, алгоритм четко их различает. Сравнение матриц ошибок для лучших моделей CatBoost и композитной модели показано на рис.7.
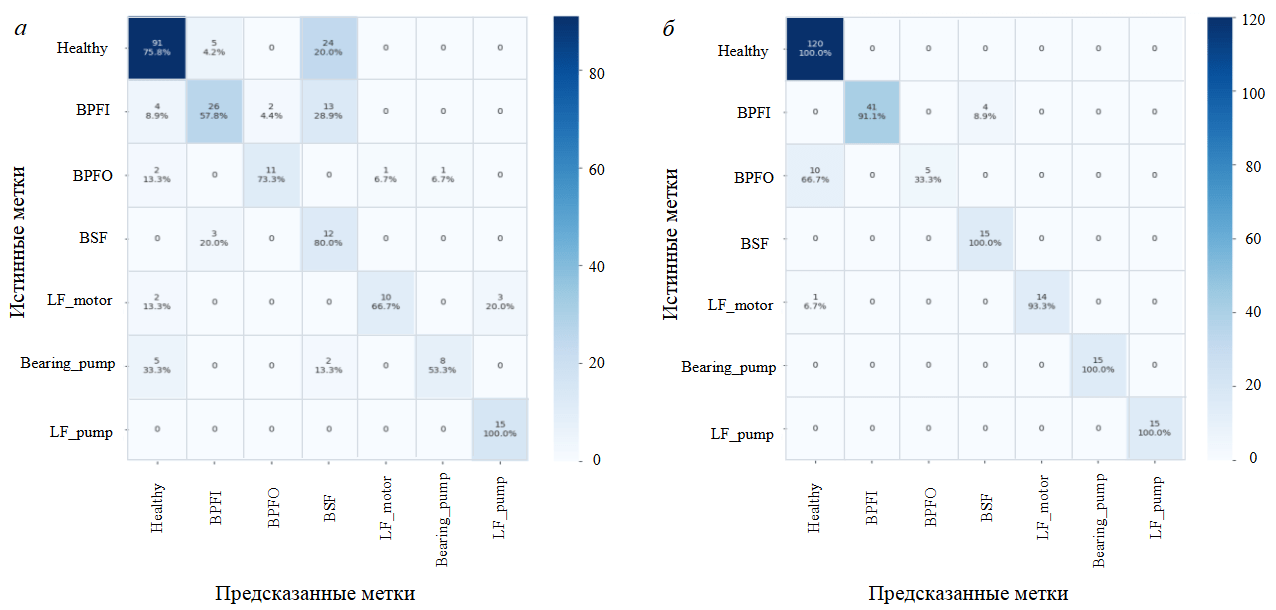
Рис.7. Сравнение матриц ошибок между CatBoost (а) и композитной моделью (б). Верхнее значение показывает общее количество классифицированных выборок, нижнее число – процент выборок, нормализованных по отношению к истинной совокупности (100 % для каждой строки)
Healthy – отсутствие каких-либо повреждений; BPFI, BPFO и BSF – неисправности, связанные с повреждениями внутренних, наружных колец и шариков подшипника двигателя; LF_motor, LF_pump – незакрепленная опора двигателя и насоса; Bearing_pump – повреждения подшипника насоса
Таблица 3
Метрика F1 для алгоритма CatBoost и композитной модели
|
Эксперимент |
CatBoost |
Композитная модель |
Эксперимент |
CatBoost |
Композитная модель |
|
NoPark |
0,68 |
0,76 |
WithInstAmp |
0,65 |
0,89 |
|
OnlyInstAmp |
0,66 |
0,65 |
FullPark |
0,64 |
0,86 |
Модели испытывают наибольшие трудности с точной классификацией повреждений внешнего и внутреннего кольца. Для обеих моделей характерна путаница между повреждениями внутреннего кольца и тел качения. Это можно объяснить тем, что нанесенные повреждения имеют раннюю степень развития дефекта и слабо выражены в сигналах, при этом рассчитанные признаки имели схожее распределение у спутанных повреждений. Для композитной модели оказалось наиболее сложно распознать повреждения внутреннего кольца. Подобное поведение демонстрировалось при предварительном выборе лучшей модели классического машинного обучения, что указывает на общую сложность распознавания этого вида дефекта. Алгоритм градиентного бустинга смог четко определить это повреждение, но имеет проблемы с другими, что может свидетельствовать о существовании некоего баланса между разделяющими классы границами. Отметим, что оба классификатора не путают большинство идентичных неисправностей мотора и насоса, что говорит о четком разграничении этих повреждений с точки зрения сгенерированных признаков. Композитная модель показала наилучшую частоту ложноположительных срабатываний в плане обнаружения аномалий маркировки исправности.
Обсуждение и ограничения
Применение алгоритма CatBoost с использованием различной комбинации дополнительных признаков не позволило достичь лучших результатов в задаче выявления таких неисправностей насосного агрегата, как повреждения подшипников двигателя (внутреннее кольцо, внешнее кольцо, шарик), повреждение подшипника насоса (одновременно внутреннее и внешнее кольцо), ослабление крепления двигателя и насоса по сравнению с предлагаемой в статье. Композитная модель показала лучшие результаты при использовании признаков, сгенерированных из мгновенных амплитуд тока и напряжения. Результаты композитной модели подтверждают предварительный анализ и ясно показывают, что расширенный вектор Парка увеличивает количество полезной информации. Исследования подтвердили, что данный подход следует применять в сочетании с необработанными данными для достижения наилучших результатов.
Важным результатом проведенных исследований является доказательство того, что классификаторы смогли различить схожие неисправности электрического мотора и насоса. Полученные результаты позволяют утверждать, что предлагаемая модель может быть обучена для обнаружения аномалий с низкой частотой ложных срабатываний даже при использовании данных с низким уровнем серьезности повреждений.
Отметим ряд практических задач, которые остались не решенными в рамках данной работы и потребуют дополнительного изучения. В настоящем исследовании мы использовали максимальную доступную скорость для мотора, но в реальности мотор может менять свои режимы работы. Для регуляции скорости в электродвигателях часто применяют частотно-регулируемые приводы, которые присутствовали при записи используемого набора данных. Приводы изменяют амплитуду и частоту питания электродвигателя, что полностью меняет записываемый сигнал и рассчитанные признаки – происходит дрейф данных. То же самое будет происходить при смене модели мотора и насоса. Из-за дрейфа качество модели может снижаться, поэтому модель должна быть заново обучена, а в некоторых случаях модифицирована для сохранения своей точности. Модификация готовых моделей возможна в рамках фреймворка FEDOT, а дообучение таких моделей проще и быстрее, чем моделей глубокого обучения. Авторы считают, что преодоление этих ограничений возможно с помощью нормализации сигнала в зависимости от скорости и нагрузки диагностируемых агрегатов либо получения индифферентных к амплитуде и частоте сигнала признаков.
Отметим ограничения по сбору данных, которые являются распространенной проблемой в промышленности. Трудно записать большое количество данных о неисправностях, так как поврежденные электрические двигатели и насосы должны быть немедленно обслужены. Классический подход машинного обучения позволяет уменьшить влияние этого ограничения по сравнению с методами глубокого обучения даже в условиях, когда доступно небольшое количество данных о неисправностях. Генеративные нейронные сети могут улучшить эту ситуацию, но все же они сталкиваются с той же нехваткой обучающих данных. Несмотря на это, такие методы начинают появляться.
Заключение
Представлен подход к классификации ряда неисправностей промышленного насоса и электрического мотора с использованием фреймворка композиции моделей, который позволяет достичь точности 0,89 макро F1-оценки. Показано, что использование расширенного вектора Парка в сочетании с необработанными данными позволяет достичь лучших результатов с учетом ограниченного количества данных для обучения.
Исследования показали, что предложенный алгоритм превосходит алгоритм градиентного бустинга при тех же самых дополнительных признаках для рассмотренных неисправностей (повреждения подшипников двигателя (внутреннее кольцо, внешнее кольцо, шарик), повреждение подшипника насоса (одновременно внутреннее и внешнее кольцо), ослабление крепления двигателя и насоса.
Установлено, что через анализ тока и напряжения с использованием предлагаемого подхода можно различать неисправности подшипников, относящиеся как к электрическому мотору, так и насосу.
Представленное исследование подчеркивает потенциал АСТД как неинвазивного и масштабируемого инструмента для мониторинга состояния оборудования, важность генерации дополнительных признаков и перспективность применения AutoML для задач технической диагностики насосных агрегатов.
С учетом практического внедрения разработанного подхода планируются дальнейшие исследования, связанные с изменением скорости вращения насосного агрегата и возникающим при этом дрейфом данных.
Литература
- Zhukovskiy Y., Buldysko A., Revin I. Induction Motor Bearing Fault Diagnosis Based on Singular Value Decomposition of the Stator Current // Energies. 2023. Vol. 16. Iss. 8. № 3303. DOI: 10.3390/en16083303
- Королев Н.А., Жуковский Ю.Л., Булдыско А.Д. и др. Оценка энергетического ресурса на основе диагностики технического состояния электромеханического оборудования минерально-сырьевого комплекса // Горный информационно-аналитический бюллетень. 2024. № 5. С. 158-181. DOI: 10.25018/0236_1493_2024_5_0_158
- Bolón-Canedo V., Morán-Fernández L., Cancela B., Alonso-Betanzos A. A review of green artificial intelligence: Towards a more sustainable future // Neurocomputing. 2024. Vol. 599. № 128096. DOI: 10.1016/j.neucom.2024.128096
- Garcia-Calva T., Morinigo-Sotelo D., Fernandez-Cavero V., Romero-Troncoso R. Early Detection of Faults in Induction Motors – A Review // Energies. 2022. Vol. 15. Iss. 21. № 7855. DOI: 10.3390/en15217855
- Atta M.E.E.-D., Ibrahim D.K., Gilany M.I. Broken Bar Fault Detection and Diagnosis Techniques for Induction Motors and Drives: State of the Art // IEEE Access. 2022. Vol. 10. P. 88504-88526. DOI: 10.1109/ACCESS.2022.3200058
- Ghanbari T., Mehraban A., Farjah E. Inter-turn fault detection of induction motors using a method based on spectrogram of motor currents // Measurement. 2022. Vol. 205. № 112180. DOI: 10.1016/j.measurement.2022.112180
- Bruinsma S., Geertsma R.D., Loendersloot R., Tinga T. Motor current and vibration monitoring dataset for various faults in an E-motor-driven centrifugal pump // Data in Brief. 2024. Vol. 52. № 109987. DOI: 10.1016/j.dib.2023.109987
- Sunal C.E., Dyo V., Velisavljevic V. Review of Machine Learning Based Fault Detection for Centrifugal Pump Induction Motors // IEEE Access. 2022. Vol. 10. P. 71344-71355. DOI: 10.1109/ACCESS.2022.3187718
- Sunal C.E., Velisavljevic V., Dyo V. et al. Centrifugal Pump Fault Detection with Convolutional Neural Network Transfer Learning // Sensors. 2024. Vol. 24. Iss. 8. № 2442. DOI: 10.3390/s24082442
- Chao Zhao, Zio E., Weiming Shen. Domain generalization for cross-domain fault diagnosis: An application-oriented perspective and a benchmark study // Reliability Engineering & System Safety. 2024. Vol. 245. № 109964. DOI: 10.1016/j.ress.2024.109964
- Kim M.-C., Lee J.-H., Wang D.-H., Lee I.-S. Induction Motor Fault Diagnosis Using Support Vector Machine, Neural Networks, and Boosting Methods // Sensors. 2023. Vol. 23. Iss. 5. № 2585. DOI: 10.3390/s23052585
- Jiusi Zhang, Ke Zhang, Yiyao An et al. An Integrated Multitasking Intelligent Bearing Fault Diagnosis Scheme Based on Representation Learning Under Imbalanced Sample Condition // IEEE Transactions on Neural Networks and Learning Systems. 2024. Vol. 35. Iss. 5. P. 6231-6242. DOI: 10.1109/TNNLS.2022.3232147
- Kumar P., Hati A.S. Review on Machine Learning Algorithm Based Fault Detection in Induction Motors // Archives of Computational Methods in Engineering. 2021. Vol. 28. Iss. 3. P. 1929-1940. DOI: 10.1007/s11831-020-09446-w
- Yakhni M.F., Cauet S., Sakout A. et al. Variable speed induction motors’ fault detection based on transient motor current signatures analysis: A review // Mechanical Systems and Signal Processing. 2023. Vol. 184. № 109737. DOI: 10.1016/j.ymssp.2022.109737
- Yuejiang Han, Jiamin Zou, Bo Gong et al. The use of model-based voltage and current analysis for torque oscillation detection and improved condition monitoring of centrifugal pumps // Mechanical Systems and Signal Processing. 2025. Vol. 222. № 111781. DOI: 10.1016/j.ymssp.2024.111781
- Chen Liang, Yan Hao, Xie Tengzhou, Li Zhiguo. Identification of cavitation state of centrifugal pump based on current signal // Frontiers in Energy Research. 2023. Vol. 11. № 1204300. DOI: 10.3389/fenrg.2023.1204300
- Господариков А.П., Ревин И.Е., Морозов К.В. Композитная модель анализа данных сейсмического мониторинга при ведении горных работ на примере Кукисвумчоррского месторождения АО «Апатит» // Записки Горного института. 2023. Т. 262. С. 571-580. DOI: 10.31897/PMI.2023.9
- Nath A.G., Udmale S.S., Singh S.K. Role of artificial intelligence in rotor fault diagnosis: a comprehensive review // Artificial Intelligence Review. 2021. Vol. 54. Iss. 4. P. 2609-2668. DOI: 10.1007/s10462-020-09910-w
- Salehin I., Islam S., Saha P. et al. AutoML: A systematic review on automated machine learning with neural architecture search // Journal of Information and Intelligence. 2024. Vol. 2. Iss. 1. P. 52-81. DOI: 10.1016/j.jiixd.2023.10.002
- Baratchi M., Can Wang, Limmer S. et al. Automated machine learning: past, present and future // Artificial Intelligence Review. 2024. Vol. 57. Iss. 5. № 122. DOI: 10.1007/s10462-024-10726-1
- Alsharef A., Aggarwal K., Sonia et al. Review of ML and AutoML Solutions to Forecast Time-Series Data // Archives of Computational Methods in Engineering. 2022. Vol. 29. Iss. 7. P. 5297-5311. DOI: 10.1007/s11831-022-09765-0
- Barandier P., Mendes M., Cardoso A.J.M. Comparative analysis of four classification algorithms for fault detection of heat pumps // Energy and Buildings. 2024. Vol. 316. № 114342. DOI: 10.1016/j.enbuild.2024.114342
- Barbudo R., Ventura S., Romero J.R. Eight years of AutoML: categorisation, review and trends // Knowledge and Information Systems. 2023. Vol. 65. Iss. 12. P. 5097-5149. DOI: 10.1007/s10115-023-01935-1
- Bischl B., Binder M., Lang M. et al. Hyperparameter optimization: Foundations, algorithms, best practices, and open challenges // WIREs Data Mining and Knowledge Discovery. 2023. Vol. 13. Iss. 2. № e1484. DOI: 10.1002/widm.1484
- Morales-Hernández A., Van Nieuwenhuyse I., Rojas Gonzalez S. A survey on multi-objective hyperparameter optimization algorithms for machine learning // Artificial Intelligence Review. 2023. Vol. 56. Iss. 8. P. 8043-8093. DOI: 10.1007/s10462-022-10359-2
- Dahiya S., Nanda H., Artwani J., Varshney J. Using Clustering techniques and Classification Mechanisms for Fault Diagnosis // International Journal of Advanced Trends in Computer Science and Engineering. 2020. Vol. 9. № 2. P. 2138-2146. DOI: 10.30534/ijatcse/2020/188922020
- Maliuk A.S., Ahmad Z., Kim J.-M. A Technique for Bearing Fault Diagnosis Using Novel Wavelet Packet Transform-Based Signal Representation and Informative Factor LDA // Machines. 2023. Vol. 11. Iss. 12. № 1080. DOI: 10.3390/machines11121080
- Hadi R.H., Hady H.N., Hasan A.M. et al. Improved Fault Classification for Predictive Maintenance in Industrial IoT Based on AutoML: A Case Study of Ball-Bearing Faults // Processes. 2023. Vol. 11. Iss. 5. № 1507. DOI: 10.3390/pr11051507
- Cerrada M., Trujillo L., Hernández D.E. et al. AutoML for Feature Selection and Model Tuning Applied to Fault Severity Diagnosis in Spur Gearboxes // Mathematical and Computational Applications. 2022. Vol. 27. Iss. 1. № 6. DOI: 10.3390/mca27010006
- Hutter F., Kotthoff L., Vanschoren J. Automated Machine Learning. Methods, Systems, Challenges. Springer, 2019. 219 p. DOI: 10.1007/978-3-030-05318-5
- Revin I., Potemkin V.A., Balabanov N.R., Nikitin N.O. Automated machine learning approach for time series classification pipelines using evolutionary optimization // Knowledge-Based Systems. 2023. Vol. 268. № 110483. DOI: 10.1016/j.knosys.2023.110483
- Javed K., Gouriveau R., Zerhouni N. State of the art and taxonomy of prognostics approaches, trends of prognostics applications and open issues towards maturity at different technology readiness levels // Mechanical Systems and Signal Processing. 2017. Vol. 94. P. 214-236. DOI: 10.1016/j.ymssp.2017.01.050
- Khan A.A., Chaudhari O., Chandra R. A review of ensemble learning and data augmentation models for class imbalanced problems: Combination, implementation and evaluation // Expert Systems with Applications. 2024. Vol. 244. № 122778. DOI: 10.1016/j.eswa.2023.122778
- Ozaki Y., Tanigaki Y., Watanabe S. et al. Multiobjective Tree-Structured Parzen Estimator // Journal of Artificial Intelligence Research. 2022. Vol. 73. P. 1209-1250. DOI: 10.1613/jair.1.13188